AlphaStar implementation series — Supervised Learning

In the past post, I showed how to solve one of the minigames of PySC2 using the Actor-Critic Reinforcement Learning algorithm. In the case of a minigame that has a simple structure, the agent does not need human expert data for behavior cloning. However, in the case of an actual 1 versus 1 game, the training time increases exponentially due to excessive numbers of states and actions. In this post, I will check that the Alpha Star Model can actually mimic the play of humans using human replay data.
Warm-Up
The simplest method for Behavior Cloning is to use the difference between the output action of the network at the replay state and the replay action as the loss value. First, try to do an experiment with the LunarLander-v2 environment of OpenAI Gym, which is a simple environment, to see if this method actually works for Actor-Critic Reinforcement Learning.
The code and dataset for that explanation can be downloaded from Google Drive.
First, I change the environment, network size of the Actor-Critic official code of Tensorflow and train it until the reward reaches 200. I use this trained model to create expert data using the below code.
Please try to understand every part of the original code because I reuse code of it to make a Supervised Learning part. Next, the loss is calculated from the difference between the action of expert data and the action of the network.
Unlike the loss of Reinforcement Learning, there is no loss for the critic network calculated by reward. You can start Supervised Learning by running the below cell of the shared Jupyter Notebook file.
The train_supervised_step is a function corresponding to the train_step function of the original code. You can train agents using the Reinforcement Learning method after finishing behavior cloning.
The run_supervised_episode function corresponds to the run_episode function that collects the data from the actual environment. This function collects expert data for Supervised Learning from the npy type files that we made before.
We can use the newly created Supervised Learning to train the Reinforcement Learning. First, save the action logit of model what we are going to train and the supervised model together.
The Kl Divergence method can be used to calculate the difference between action logits because they are a probabilistic distribution.
The KL loss calculated is added to the RL loss to train the model.
In this way, the agent can learn faster than using Reinforcement Learning alone, as shown in the graph below.
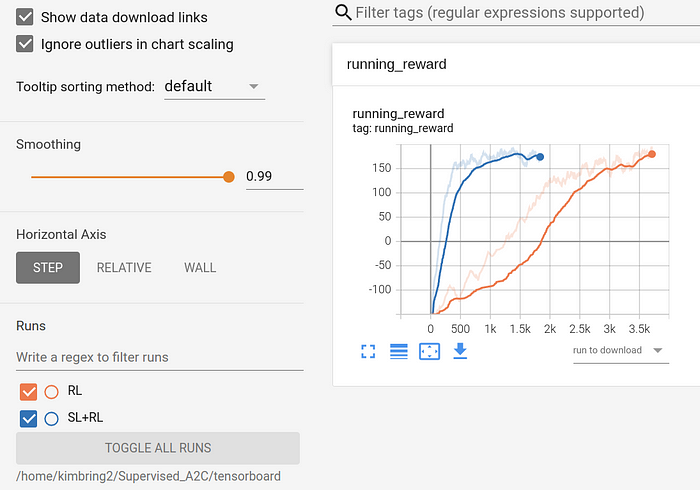
Supervised Learning for Starcraft 2
In the case of the LunarLander-v2 environment, it can be solved sufficiently by using only Reinforcement Learning. However, it is common to use Supervised Learning together as in the case of Starcraft 2 which has complicated observation and action space to shorten the training time. In the case of the LunarLander-v2 environment, data can be generated using the model trained from Reinforcement Learning, and loss is calculated for only one action. However, for Starcraft 2 case, humans need to play the game directly to collect data, and action type and all 13 action arguments need to be considered for loss.
- Replay file of Terran vs Terran at Simple64 map using two barracks marine rush: https://drive.google.com/drive/folders/1lqb__ubLKLfw4Jiig6KsO-D0e_wrnGWk
- Supervised Training code for PySC2: https://github.com/kimbring2/AlphaStar_Implementation
After downloading the replay file, you need to convert it to hkl file format. See https://github.com/kimbring2/AlphaStar_Implementation#supervised-training for detailed instructions.
The code below basically uses One-Hot Encoding, Categorical Cross-Entropy, and L2 Regularization to calculate the loss for Supervised Learning in Pysc2, similar to the LunarLander-v2 environment.
However, in the case of Starcraft2, even if a human executes a specific action type, it may not be reflected depending on whether it is available in the current game. Therefore, it is filtered via the available_actions feature. Furthermore, even in the case of the action argument, it is also filtered because specific action types only need a limited action argument.
The following graph is a loss of Supervised Learning for Starcraft2. Due to the complexity of action and observation space, it takes a very long time to train.
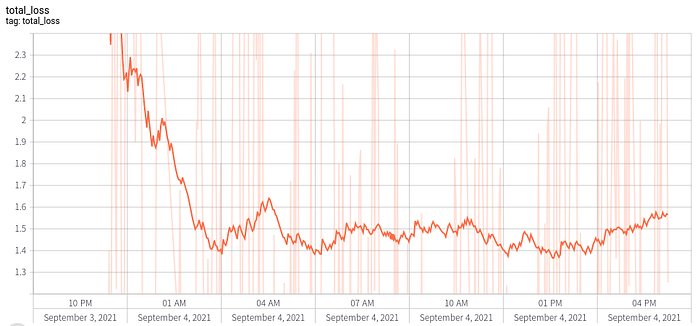
The following video is the evaluation result of the trained model around 5 days using about 1000 expert data. We can confirm that agent imitates human behavior to some level.
Conclusion
In this post, we investigate the Supervised Learning method using expert data in Actor-Critic Reinforcement Learning in the case of Starcraft 2. Considering that almost all actual environments outside the laboratory are complicated. Human data and loss calculation for multiple action methods should be considered essential for agent development of high performance.

